Hey everyone! Welcome to the first part of this blog series on the io_uring subsystem.
Introduction
The io_uring subsystem is designed to improve the performance and efficiency of asynchronous I/O operations, particularly for high throughput and low-latency applications that deal with a lot of data transfer.
Traditionally, asynchronous I/O in Linux has been implemented using interfaces like epoll, aio, and select, which have limitations in terms of scalability and efficiency, especially when dealing with large numbers of concurrent I/O operations. The term io_uring originates from its reliance on ring buffers (or circular buffers, or queue rings) as the primary means of communication between the kernel and user space. While there are some system calls involved, they’re used sparingly, and there’s a polling mode that helps reduce how often they’re needed.
The ring buffers facilitate communication between kernel and user space. These buffers are shared between user space and kernel space. There are two types of circular buffers: the Submission Queue (SQ) and the Completion Queue (CQ). Operations to be executed are submitted to the Submission Queue, and upon completion, the kernel places the results into the Completion Queue.
Work
We need to create and setup shared buffers for the submission queue and the completion queue. This can be done using the io_uring_setup system call. This system call sets up a submission queue and a completion queue, and returns a file descriptor which can be used to perform subsequent operations on the io_uring instance.
Note: For kernel versions >= 5.4, we can use a single mmap for mapping both, submission and completion buffers. This can be done by checking the value of the features field of the struct io_uring_params,which is a bitmask. If IORING_FEAT_SINGLE_MMAP is set, we can use this feature.
First of all, let’s write a wrapper function that executes the io_uring_setup system call.
The entries parameter represents the number of entries that can be held by the submission queue and the completion queue. The variable p over here will be populated if the system call executes successfully. We’re also gonna create a wrapper function for throwing errors.
Now, we’re going to create some data structures for storing critical information needed later. These data structures will be initialized in the main() function.
// p will get populated if the io_uring_setup system call works ring_fd = io_uring_setup(QUEUE_DEPTH, &p); if (ring_fd == -1) { fatal_error("error: io_uring_setup failed"); } /* We're determining the respective sizes of the the shared kernel-user space ring buffers */ sring_size = p.sq_off.array + p.sq_entries * sizeof(unsigned); cring_size = p.cq_off.cqes + p.cq_entries * sizeof(struct io_uring_cqe); /* For linux kernel versions >=5.4 , both submission and completion buffers can be allocated using a single mmap. Instead of checking for the exact version, we can utilize the features field present within the struct io_uring_params, which is a bitmask. */ int single_mmap_allowed = p.features & IORING_FEAT_SINGLE_MMAP; /* If single mmap is allowed, the sizes of the submission ring (sring_size) and the completion ring (cring_size) must be equal, set to the larger value of the two */ if (single_mmap_allowed) { if (sring_size > cring_size) { cring_size = sring_size; } sring_size = cring_size; } // Mapping the submission and completion queue ring buffers squeue_ptr = mmap(0, sring_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE, ring_fd, IORING_OFF_SQ_RING); if (squeue_ptr == MAP_FAILED) { fatal_error("error: mmap failed"); } if (single_mmap_allowed) { // For kernel versions >= 5.4 cqueue_ptr = squeue_ptr; } else { // For older kernel versions cqueue_ptr = mmap(0, cring_size, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE, ring_fd, IORING_OFF_CQ_RING); if (cqueue_ptr == MAP_FAILED) { fatal_error("error: mmap failed"); } } // Next, we need to map in the submission queue entries array /* Recall, sring_size = p.sq_off.array + p.sq_entries * sizeof(unsigned); The addition of p.sq_off.array to the length of the region accounts for the fact that the ring is not located right at the beginning. The actual array of submission-queue entries, instead, is mapped with: */ sring_metadata->tail = squeue_ptr + p.sq_off.tail; sring_metadata->array = squeue_ptr + p.sq_off.array; sring_metadata->mask = squeue_ptr + p.sq_off.ring_mask; sqes = mmap(0, p.sq_entries * sizeof(struct io_uring_sqe), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_POPULATE, ring_fd, IORING_OFF_SQES); if (sqes == MAP_FAILED) { fatal_error("error: mmap failed"); }
// Let's save some important fields for later use cring_metadata->head = cqueue_ptr + p.cq_off.head; cring_metadata->tail = cqueue_ptr + p.cq_off.tail; cring_metadata->mask = cqueue_ptr + p.cq_off.ring_mask;
/* We're not creating a new memory mapping because the completion queue ring directly indexes the shared array of Completion Queue Entries */ cqes = cqueue_ptr + p.cq_off.cqes; }
Having completed the setup, now we’re ready to perform read and write operations. Before writing the code for the functions responsible for handling the submission and the completion queues, let’s create two macros for performing atomic load and store operations. Atomic operations are used to ensure safe and synchronized access to shared memory data structures in a multi-threaded or multi-core environment.
intsubmit_to_sq(int fd, int op) { // New entries are added to the tail of the submission queue. unsigned index, tail; tail = *sring_metadata->tail; /* To get the index of an entry, the current tail index must be masked with the size mask of the ring */ index = tail & *sring_metadata->mask; // Retrieving the entry from the submission queue entries structio_uring_sqe *sqe = &sqes[index]; /* opcode indicates the type of operation that must be done such as IORING_OP_READ for reading and IORING_OP_WRITE for writing */ sqe->opcode = op; // File descriptor of the target file sqe->fd = fd; // Assigning the buffer address sqe->addr = (unsignedlong)buffer; if (op == IORING_OP_READ) { memset(buffer, 0, sizeof(buffer)); // We wanna read n_read number of bytes sqe->len = n_read; } else { sqe->len = strlen(buffer); }
sring_metadata->array[index] = index; // Update the tail tail++; io_uring_smp_store(sring_metadata->tail, tail);
/* After adding one or more submission queue entries, we need to call io_uring_enter to tell the kernel to dequeue the I/O requests off the submission queue and begin processing them */ int ret = io_uring_enter(ring_fd, 1, 1, IORING_ENTER_GETEVENTS); /* Returns the number of I/Os successfully consumed. However, this might not be the case if the ring was created using IORING_SETUP_SQPOLL */ if (ret < 0) { fatal_error("io_uring_enter failed"); }
return ret; }
Now, let’s write a function for reading from the completion queue
intread_from_cq() { // Reads are performed from the head of the completion queue structio_uring_cqe *cqe; unsigned head, index;
head = io_uring_smp_load(cring_metadata->head); /* To get the index of an entry, the current tail index must be masked with the size mask of the ring */ index = head & (*cring_metadata->mask); // Head and tail will be at the same position if the circular buffer is empty if (head == *cring_metadata->tail) { return-1; }
cqe = &cqes[index]; if (cqe->res < 0) { fatal_error(strerror(abs(cqe->res))); }
/* Note: the kernel adds completion queue entries to the tail of the completion queue, but they must be dequeued from the head. */ head++; // Atomically update the head io_uring_smp_store(cring_metadata->head, head); return cqe->res; }
Having created the functions for dealing with the SQ and the CQ, we’re ready to create the main function.
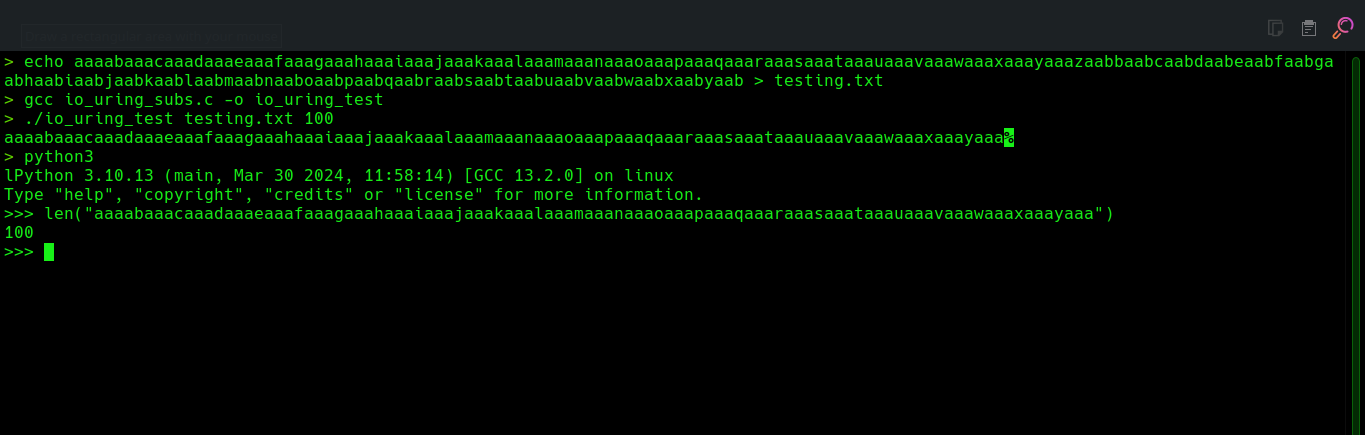
intmain(int argc, char *argv[]) { if(argc <= 2){ fatal_error("error: you must supply a valid path and the number of bytes to read"); } int res; n_read = atoi(argv[2]); // Allocate memory for the data structures and initialize them to zero sring_metadata = (ring_metadata *)calloc(sizeof(ring_metadata), 1); cring_metadata = (ring_metadata *)calloc(sizeof(ring_metadata), 1);
buffer = (char *)calloc(n_read, 1);
setup_io_uring(); int fd = open(argv[1], O_RDONLY); if (fd == -1) { fatal_error("failed to open the file"); }
submit_to_sq(fd, IORING_OP_READ);
res = read_from_cq(); if(res<=0){ fatal_error("error: couldn't read from the completion queue"); } submit_to_sq(STDOUT_FILENO, IORING_OP_WRITE); return0; }
intmain(int argc, char *argv[]) { if(argc <= 2){ fatal_error("error: you must supply a valid path and the number of bytes to read"); } int res; n_read = atoi(argv[2]); sring_metadata = (ring_metadata *)calloc(sizeof(ring_metadata), 1); cring_metadata = (ring_metadata *)calloc(sizeof(ring_metadata), 1);
buffer = (char *)calloc(n_read, 1);
setup_io_uring(); int fd = open(argv[1], O_RDONLY); if (fd == -1) { fatal_error("failed to open the file"); }
submit_to_sq(fd, IORING_OP_READ);
res = read_from_cq(); if(res<=0){ fatal_error("error: couldn't read from the completion queue"); } submit_to_sq(STDOUT_FILENO, IORING_OP_WRITE); return0; }
So, that’s all for this blog. In the next part of this series, we’ll be developing a multithreaded TCP chat server using the io_uring subsystem.